1. Loss Functions
Our model is optimized for a multi-task loss function that consists of seven losses:
\begin{equation}
\begin{split}
\mathcal{L} &= \lambda_1 \mathcal{L}_{{Image}_{type}} + \lambda_2 \mathcal{L}_{{Image}_{orientation}} \\
& + \lambda_3 \mathcal{L}_{{RoI}_{objectness}} + \lambda_4 \mathcal{L}_{{RoI}_{bbox}} \\
& + \lambda_5 \mathcal{L}_{{DT}_{type}} + \lambda_6 \mathcal{L}_{{DT}_{bbox}} + \lambda_7
\mathcal{L}_{{DT}_{mask}}
\end{split}
\end{equation}
The summary of these losses is presented in the above table.
The hyper-parameters \(\lambda\) control the balance between these seven task losses.
We note that the losses defined on the entire image (i.e., \(\mathcal{L}_{{Image}_{type}}\) and
\(\mathcal{L}_{{Image}_{orientation}}\))
are not on the same scale with other losses (which are defined on the local regions of the image).
Therefore, we empirically set a smaller \(\lambda\) to them (i.e., 0.15)
and follow previous works ref_fast_rcnnref_rpnref_mask_rcnn to
keep other losses as 1.
The detail computation of each loss is described as follows:
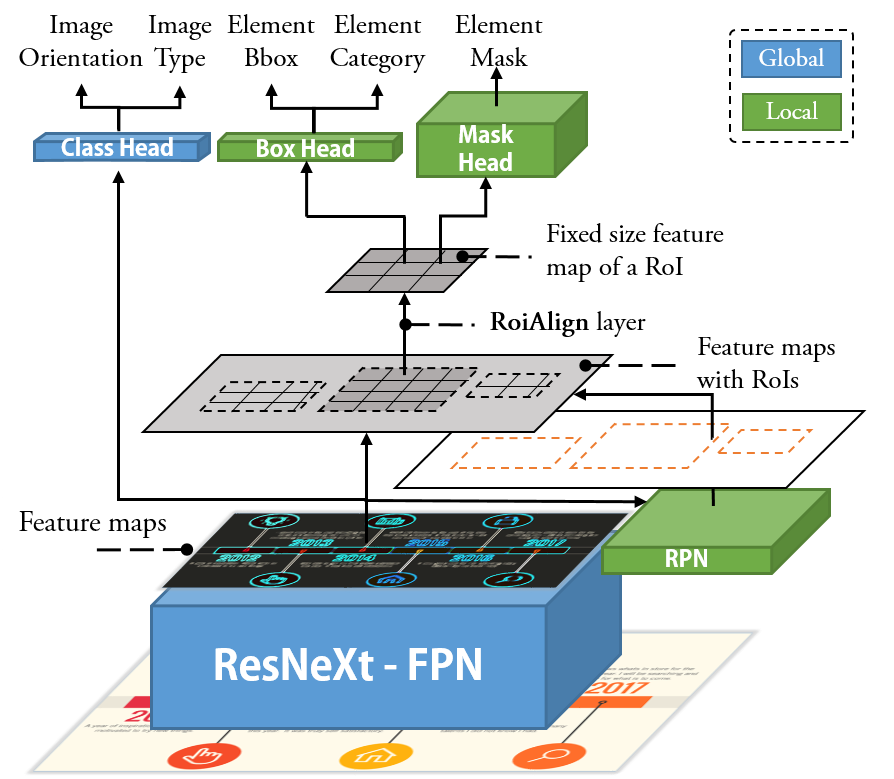
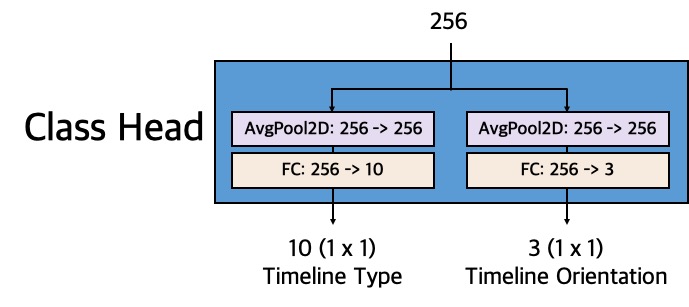
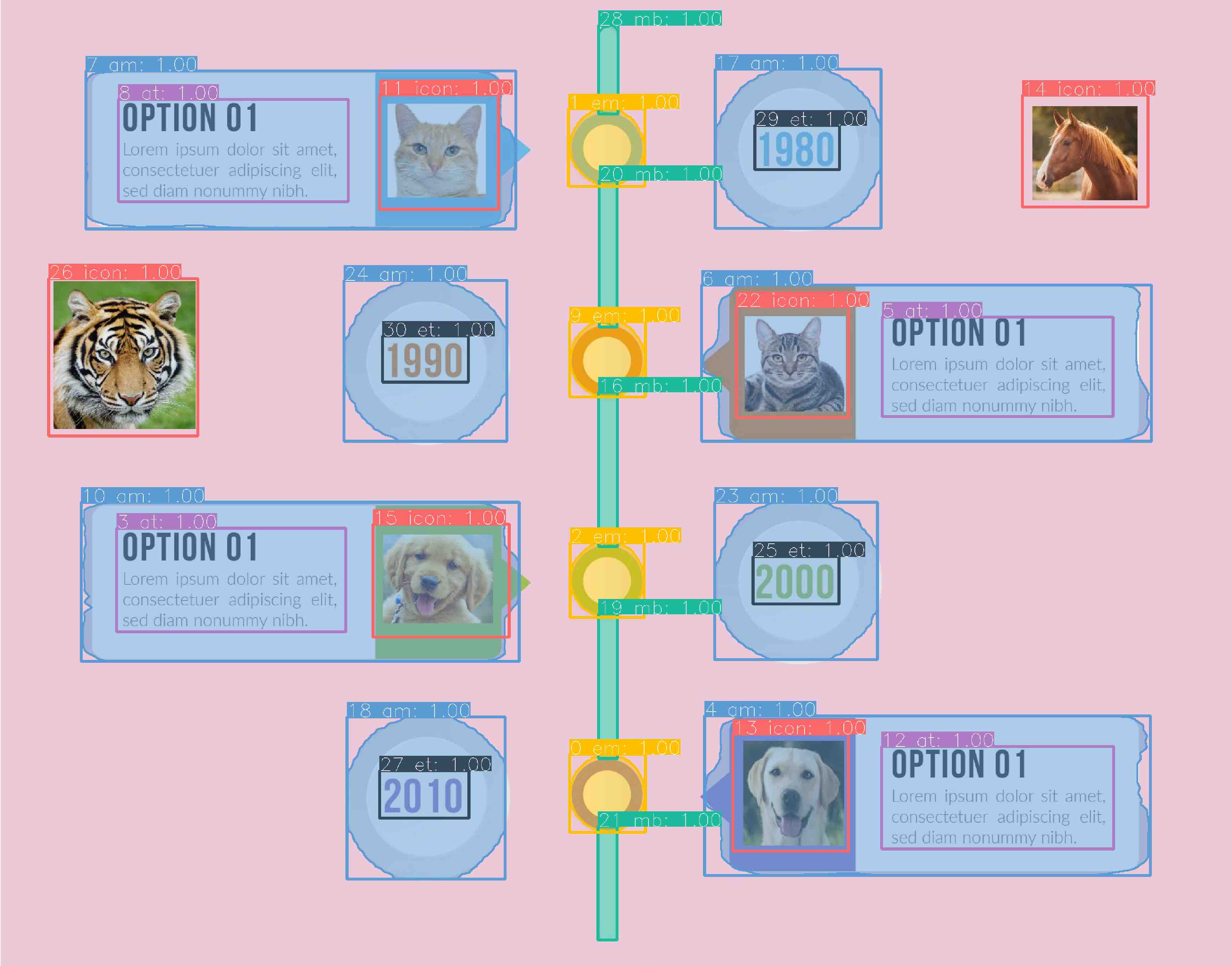
\(\mathcal{L}_{{Image}_{type}}\)
The \(\mathcal{L}_{{Image}_{type}}\), defined on the entire image,
is computed using the output on the timeline type from Class Head.
The output is a discrete probability distribution \(p = (p_1, ..., p_{10})\) over 10 timeline types
computed by a softmax function.
The timeline type classification loss is a log loss for the true type \(u:
\mathcal{L}_{{Image}_{type}}(p, u) = -\log{p}_{u}\).
\(\mathcal{L}_{{Image}_{orientation}}\)
The \(\mathcal{L}_{{Image}_{orientation}}\), defined on the entire image,
is computed using the output on the timeline orientation from Class Head.
The output is a discrete probability distribution \(p = (p_1, p_2, p_3)\) over 3 timeline
orientations computed by a softmax function.
The timeline orientation classification loss is a log loss for the true orientation \(u:
\mathcal{L}_{{Image}_{orientation}}(p, u) = -\log{p}_{u}\).
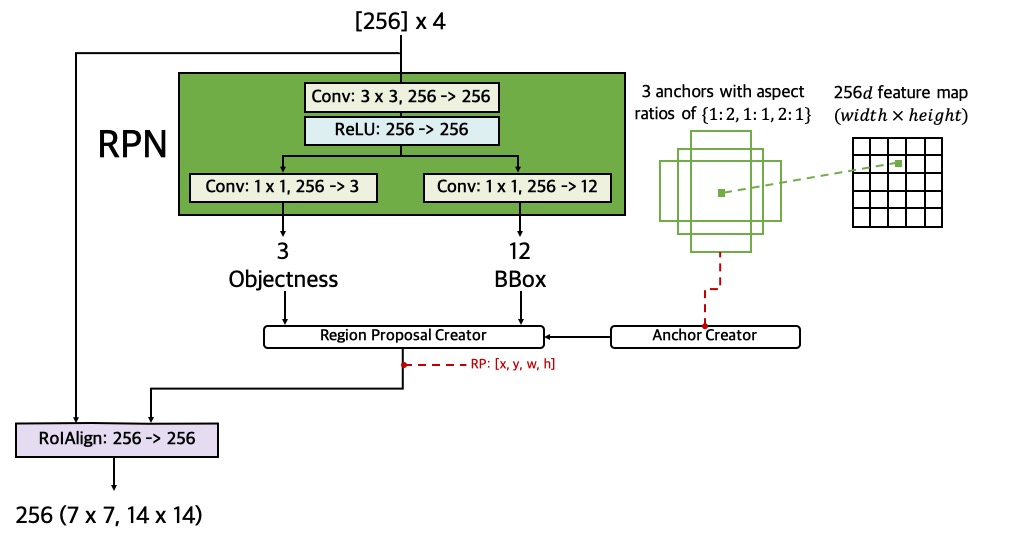
\(\mathcal{L}_{{RoI}_{objectness}}\)
The \(\mathcal{L}_{{RoI}_{objectness}}\), defined on each RoI,
is computed using the output on the objectness from RPN.
For each RoI, RPN uses a softmax
function to compute a
probability \(p\) to predict whether the RoI contains objects or not (i.e., foreground
vs. background).
The ground truth \(p^*\) is 1 if a RoI is foreground, and is 0 if it is background.
The objectness classification loss is a log loss over two classes:
\(\mathcal{L}_{{RoI}_{objectness}}(p, p^*) = - p^* \log p - (1 - p^*) \log (1 - p)\).
We refer the reader to ref_rpn for more details.
\(\mathcal{L}_{{RoI}_{bbox}}\)
The \(\mathcal{L}_{{RoI}_{bbox}}\), defined on each RoI,
is computed using the output on the bbox from RPN.
For each RoI, RPN outputs bbox
correction \(t = (t_x, t_y, t_w, t_h)\)
of the anchor associated with the RoI. The regression loss is computed using Smooth \(L_1\) on the
prediction \(t\) and ground truth \(t^* \):
\begin{equation}
\mathcal{L}_{{RoI}_{bbox}}(t, t^*) = p^* L_1^\text{smooth}(t - t^*),
\end{equation}
where \( L_1^\text{smooth}(x) = \begin{cases}0.5 x^2 & \text{if} \vert x \vert < 1 \\ \vert x \vert
- 0.5 & \text{otherwise} \end{cases}\), and the term \(p^*\) indicates that the loss is
activated only for foreground RoI (\(p^*=1\)) and is disabled otherwise (\(p^*=0\)). We refer
the reader to ref_rpn for more details.
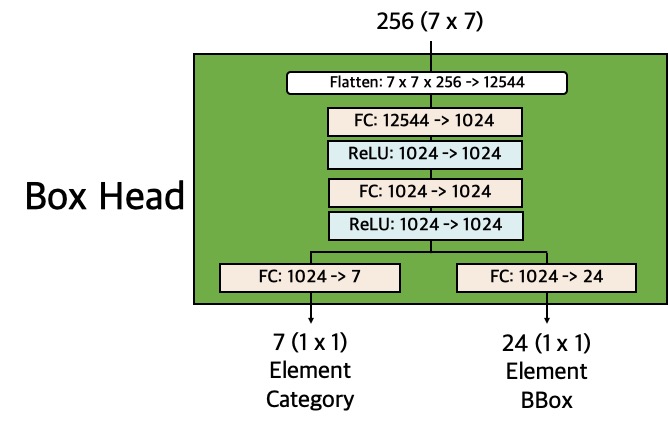
\(\mathcal{L}_{{DT}_{type}}\)
The \(\mathcal{L}_{{DT}_{type}}\), defined on each detection (i.e., DT),
is computed using the output on the element category from Box Head.
For each DT, Box Head uses a
softmax function to compute a
discrete probability distribution \(p = (p_0, p_1, ..., p_6)\) over six pre-defined element
categories and a "catch all" background.
The element category classification loss is a log loss for the true category \(u:
\mathcal{L}_{{DT}_{type}}(p, u) = -\log{p}_{u}\).
\(\mathcal{L}_{{DT}_{bbox}}\)
The \(\mathcal{L}_{{DT}_{bbox}}\), defined on each DT,
is computed using the output on the element bbox from Box Head.
For each DT,
Box Head outputs 6 bbox regression
corrections, \(t^k = (t^k_x, t^k_y, t^k_w, t^k_h)\) indexed by \(k\),
one for each of the 6 categories.
We use the parameterization for \(t^k\) given in ref_fast_rcnn,
in which \(t^k\) specifies a
scale-invariant translation and log-space height/width shift relative to a region proposal (RoI).
Similar to \(\mathcal{L}_{{RoI}_{bbox}}\), the regression loss \(\mathcal{L}_{{DT}_{bbox}}\)
is also computed using Smooth \(L_1\): \(\mathcal{L}_{{RoI}_{bbox}}(t^u, t^*) = [u > 0]
L_1^\text{smooth}(t^u - t^*) \),
where \(t^u\) is the predicted bbox correction of the true category \(u\) and \(t^*\) is the ground
truth.
The Iverson bracket indicator function
\([u > 0]\) evaluates to 1 when \(u > 0\) and 0 otherwise,
which means the loss is only activated on the foreground predictions (\(p_1\) to \(p_6\)), since the
"catch all" background class is labeled \(u = 0\) by convention.
We refer the reader to ref_fast_rcnn for more details.
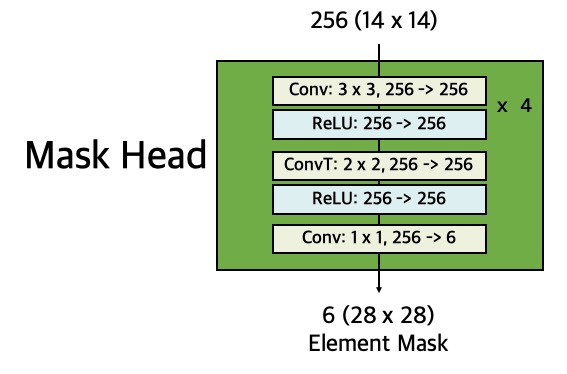
\(\mathcal{L}_{{DT}_{mask}}\)
The \(\mathcal{L}_{{DT}_{mask}}\), defined on each DT,
is computed using the output of Mask
Head.
For each DT, Mask Head outputs 6
binary masks of resolution \(m \times m \) (defined as a hyper parameter),
one for each of the 6 categories. \(\mathcal{L}_{{DT}_{mask}}\) is defined as the average binary
cross-entropy loss over all pixels of a mask.
Besides, for an DT associated with its ground true category \(u\), the loss is only defined in the
\(u\)-th mask (other mask outputs do not contribute to the loss):
\( \mathcal{L}_{{DT}_{mask}} = - [u > 0] \frac{1}{m^2} \sum_{1 \leq i, j \leq m} \big[ p^*_{ij} \log
p^u_{ij} + (1-p^*_{ij}) \log (1- p^u_{ij}) \big] \),
where \(p^*_{ij}\) is the label of a pixel \((i, j)\) in the true mask
and \(p^u_{ij}\) is the predicted label of the same pixel for the true category \(u\); the term \([u
> 0]\) works in the same manner as in \(\mathcal{L}_{{DT}_{bbox}}\).
We refer the reader to ref_mask_rcnn for more details.
2. Hyper parameters
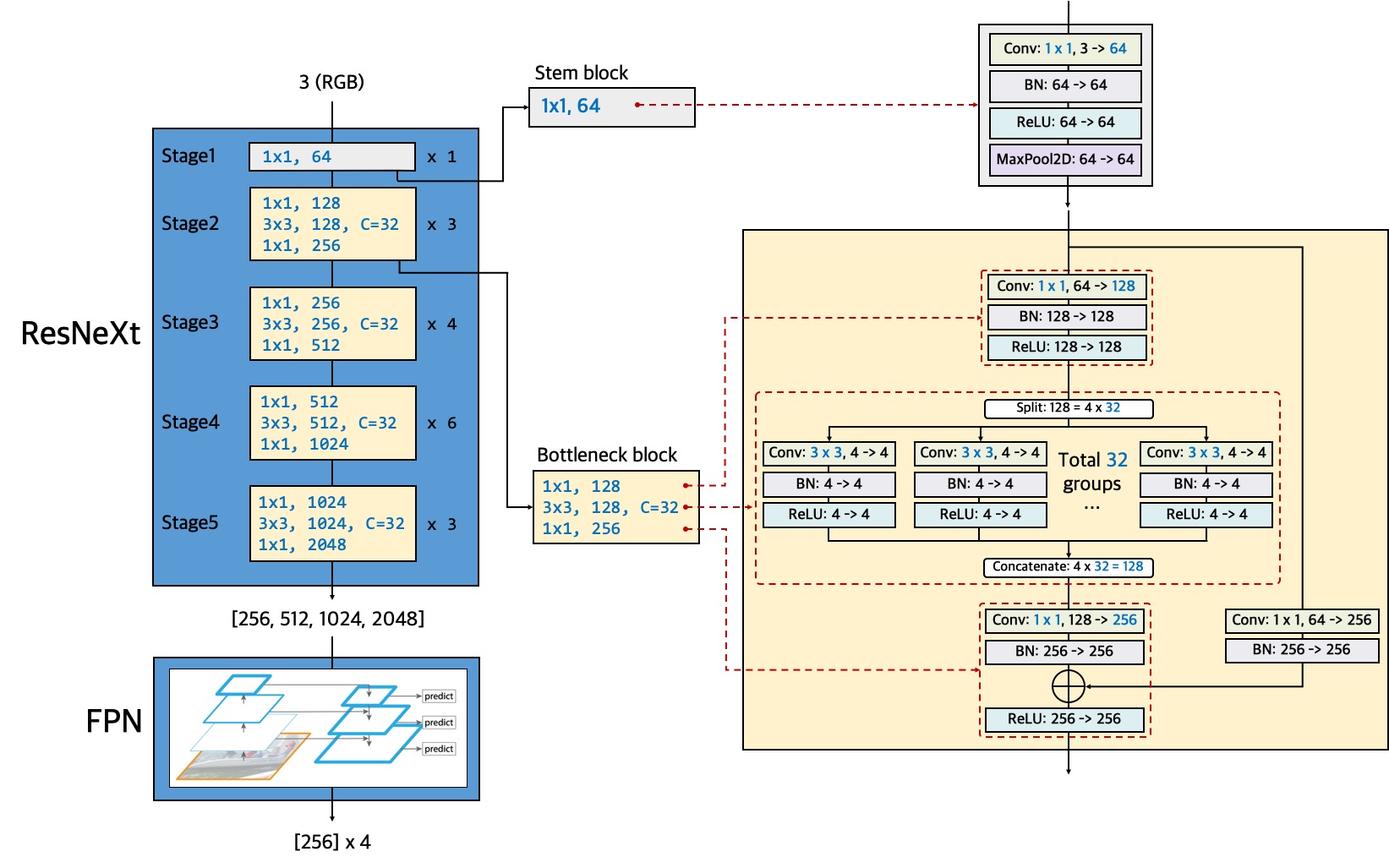
We implemented two types of CNN backbone for our model, namely, ResNeXt-101 and ResNeXt-50.
Below are the hyper parameters we used to train our models with ResNeXt-101 and ResNeXt-50, respectively.
MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
WEIGHT: "catalog://ImageNetPretrained/FAIR/20171220/X-101-32x8d"
BACKBONE:
CONV_BODY: "R-101-FPN"
OUT_CHANNELS: 256
CLASSIFIER:
NUM_CLASSES: 10
CLASSIFIER2:
NUM_CLASSES: 3
RPN:
USE_FPN: True
ANCHOR_STRIDE: (4, 8, 16, 32, 64)
PRE_NMS_TOP_N_TRAIN: 2000
PRE_NMS_TOP_N_TEST: 1000
POST_NMS_TOP_N_TEST: 1000
FPN_POST_NMS_TOP_N_TEST: 1000
ROI_HEADS:
USE_FPN: True
BATCH_SIZE_PER_IMAGE: 256
ROI_BOX_HEAD:
POOLER_RESOLUTION: 7
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
POOLER_SAMPLING_RATIO: 2
FEATURE_EXTRACTOR: "FPN2MLPFeatureExtractor"
PREDICTOR: "FPNPredictor"
NUM_CLASSES: 7
ROI_MASK_HEAD:
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
FEATURE_EXTRACTOR: "MaskRCNNFPNFeatureExtractor"
PREDICTOR: "MaskRCNNC4Predictor"
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 2
EXCLUDE_LABELS: (0, 3)
RESOLUTION: 28
SHARE_BOX_FEATURE_EXTRACTOR: False
RESNETS:
STRIDE_IN_1X1: False
NUM_GROUPS: 32
WIDTH_PER_GROUP: 8
MASK_ON: True
CLASSIFIER_ON: True
CLASSIFIER2_ON: True
INPUT:
MIN_SIZE_TRAIN: 833
MAX_SIZE_TRAIN: 1024
MIN_SIZE_TEST: 833
MAX_SIZE_TEST: 1024
DATALOADER:
SIZE_DIVISIBILITY: 32
ASPECT_RATIO_GROUPING: False
SOLVER:
BASE_LR: 0.005
WEIGHT_DECAY: 0.0001
STEPS: (56000, 76000)
# Epoch = (MAX_ITER * IMS_PER_BATCH) / #dataset
MAX_ITER: 84000
IMS_PER_BATCH: 4
CHECKPOINT_PERIOD: 10000
MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
WEIGHT: "catalog://ImageNetPretrained/MSRA/R-50"
BACKBONE:
CONV_BODY: "R-50-FPN"
OUT_CHANNELS: 256
CLASSIFIER:
NUM_CLASSES: 10
CLASSIFIER2:
NUM_CLASSES: 3
RPN:
USE_FPN: True
ANCHOR_STRIDE: (4, 8, 16, 32, 64)
PRE_NMS_TOP_N_TRAIN: 2000
PRE_NMS_TOP_N_TEST: 1000
POST_NMS_TOP_N_TEST: 1000
FPN_POST_NMS_TOP_N_TEST: 1000
ROI_HEADS:
USE_FPN: True
BATCH_SIZE_PER_IMAGE: 256
ROI_BOX_HEAD:
POOLER_RESOLUTION: 7
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
POOLER_SAMPLING_RATIO: 2
FEATURE_EXTRACTOR: "FPN2MLPFeatureExtractor"
PREDICTOR: "FPNPredictor"
NUM_CLASSES: 7
ROI_MASK_HEAD:
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
FEATURE_EXTRACTOR: "MaskRCNNFPNFeatureExtractor"
PREDICTOR: "MaskRCNNC4Predictor"
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 2
RESOLUTION: 28
SHARE_BOX_FEATURE_EXTRACTOR: False
MASK_ON: True
CLASSIFIER_ON: True
CLASSIFIER2_ON: True
INPUT:
MIN_SIZE_TRAIN: 833
MAX_SIZE_TRAIN: 1024
MIN_SIZE_TEST: 833
MAX_SIZE_TEST: 1024
DATALOADER:
SIZE_DIVISIBILITY: 32
ASPECT_RATIO_GROUPING: False
SOLVER:
BASE_LR: 0.005
WEIGHT_DECAY: 0.0001
STEPS: (56000, 76000)
# Epoch = (MAX_ITER * IMS_PER_BATCH) / #dataset
MAX_ITER: 84000
IMS_PER_BATCH: 4
CHECKPOINT_PERIOD: 10000